This is another project that was born out of anger.
As I write this in late October 2025, we are now 9 months into the second Trump presidency. It’s been hard keeping track of all that has been damaged and destroyed within the federal government. Emboldened by Musk and the absence of oversight, the so-called “Department of Government Efficiency” (DOGE) went rampaging through agencies to subvert their security, cancel contracts, fire staff and siphon up confidential data into large data warehouses. Some of this was motivated by Silicon Valley’s empty libertarian platitudes about disruption and efficiency. Much of this was to be the point of the spear for Russell Vought’s plan to subvert the Constitution.
As someone who has spent the past decade of my live in Civic Tech, this has been extremely demoralize to watch. Not only are they destroying vital government services, they’re undermining the idea that technology can serve the public good. I feel compelled to bear witness to this moment, but ‘m not particularly good at writing commentary. I’m no longer adjacent enough to journalism that I can report on what is happening. However, I do enjoy working with data and seeing what patterns will emerge over time from data collection and analysis.
And so, I created a new GitHub repo named trump_data on February 8th, 2025. And then, I started collecting data. The first datasets were relatively modest in scope:
- I wrote a script for pulling data from the Just Security Litigation Tracker to see how cases changed over time
- I created a dataset for tracking Trump’s trips to one of his various properties and what days he went golfing. This turned out to be easier to just hand-edit rather than write a scraper for it. More recently, John Emerson contributed an automated scraper to find the golf dates so I don’t need to update those manually
- I added a table of CSV data recording the population at the concentration camp in Guantanamo Bay that Trump promised to create for immigration detention
- I started collecting the weekly unemployment reports to see if it would start showing a surge in unemployment for federal employees
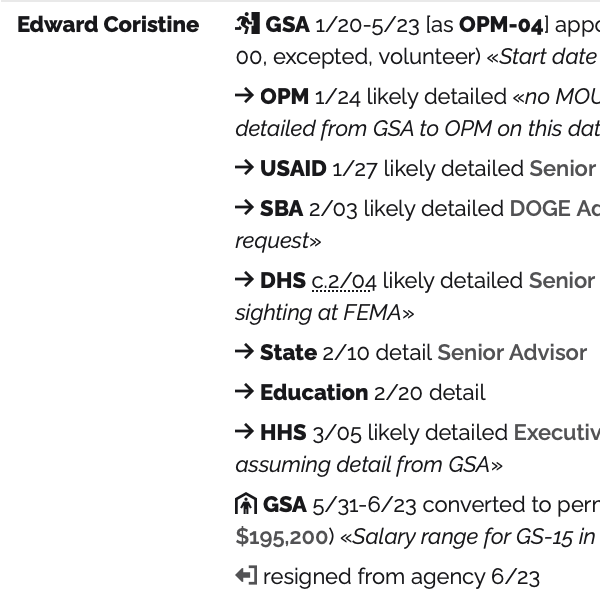
My biggest project within the repository has turned out to be an evolving effort to track the activities of DOGE’s “IT Modernization” efforts across the federal government. Practically every single example of DOGE’s smash-and-grab assaults on a given federal agency starts with the lie that they’re just there to help the agency with “IT modernization” before they quickly escalate their privileges, lock out staff, cancel contracts and fire much of the staff. I was tired of how much they operated in the shadows, so I started collecting data from news sources of their activities.
Evolving the IT Modernization Dataset
It started simply enough as a single YAML file, with the following basic structure:
- agency: Centers for Medicare and Medicaid Services
acronym: CMS
date_started: 2025-02-05
date_completed:
participants:
- Luke Farritor
vandalism:
systems:
- name: CMS Acquisition Lifecycle Management system
acronym: CALM
description: System for tracking CMS acquisitions, contracts, milestones and audits.
sources:
- https://www.msn.com/en-us/money/general/doge-targets-u-s-health-agencies-gains-access-to-payment-systems/ar-AA1yu5OD
- https://www.cms.gov/newsroom/press-releases/cms-statement-collaboration-doge
- https://www.wsj.com/politics/elon-musk-doge-medicare-medicaid-fraud-e697b162I just wanted to track who was at each agency and what was happening. I chose YAML because it is a data format that is designed for machine-processing but it is also meant to be somewhat readable for non-technical people if they wanted to also read the data From there, I have kept evolving both the types of data I’m collecting and the systems for keeping track of it all with a variety of iterations:
- I added an
eventsfield where I started listing the dates and details of specific events, always with a linked source for attribution and reconstruction - I added a
namedfield to theeventstructure to record when specific DOGE staff were associated with events - I added a
roundupssection for listing when news sites published roundups of who is where. I also started recording more info for systems. - To make it more accessible to non-programmers, I built a script to create a CSV version of events that could be loaded in Excel
- While working on that, I discovered that I had made some formatting errors in the YAML file and I was sometimes inconsistent with field names. So, I created a JSON Schema file to validate the YAML so my editor could tell me when I was introducing errors.
- I then extended that YAML schema to also include Enumerated field types for the DOGE names so I would never have to worry about keeping it consistent for people (e.g., Mike Russo in one place and Michael Russo in other places). I used that for also validating agency abbreviations and system acronyms.
- I added a
typefield and defined several basic event types so I could differentiate between things like “DOGE staff were spotted at an agency” from “a specific DOGE staffer was granted access to several systems” or “a person was detailed form one agency to another” - I added support for imprecise dates, so I would be able to better represent the fuzziness of a news article reporting that something happened “late last week” vs. an exact date
At this point, the YAML looked more like this for a single agency
- name: Department of the Interior
acronym: DOI
roundups:
- source: https://www.nytimes.com/interactive/2025/02/27/us/politics/doge-staff-list.html
organization: The New York Times
named:
- Tyler Hassen
- source: https://projects.propublica.org/elon-musk-doge-tracker/
organization: ProPublica
named:
- Tyler Hassen
- source: https://www.wired.com/story/elon-musk-doge-silicon-valley-corporate-connections/
organization: Wired Magazine
date: 2025-03-28
named:
- Tyler Hassen
events:
- date: 2025-01-28
type: disruption
event: Two DOGE staffers attempted to force water pumps to be turned on in a large reservoir in California for a photo op
named:
- Tyler Hassen
- Bryton Shang
source: https://www.cnn.com/2025/03/07/climate/trump-doge-california-water/index.html
- date: 2025-02-24
type: onboarded
onboard_type: detailed
event: Stephanie Holmes is detailed to the Department of the Interior as a Special Advisor and acting Chief Human Capital Officer for the entire agency
detailed_from: DOGE
named:
- Stephanie Holmes
source: https://subscriber.politicopro.com/article/eenews/2025/03/05/heres-the-people-connected-to-doge-at-interior-00213330
- date: 2025-03-04
type: disruption
event: DOGE boasts in a tweet that 27% more water was released in February compared to January (unclear if this adjusts for different lengths of months)
source: https://xcancel.com/DOGE/status/1896948512975433787
- date: 2025-03-07
type: promotion
event: Tyler Hassen is promoted to Acting Assistant Secretary of Policy, Management and Budget
named:
- Tyler Hassen
source: https://www.eenews.net/articles/doge-official-appointed-head-of-policy-at-interior/
- date: 2025-03-28
type: report
event: Expressing concerns about DOGE requesting access to FPPS, the CIO and CISO of the Department of the Interior present a memo to the Interior Secretary about the risks for him to acknowledge and sign. He doesn't sign it
source: https://www.nytimes.com/2025/03/31/us/politics/doge-musk-federal-payroll.html
- date: 2025-03-28
type: disruption
event: Tyler Hassen places the CIO and CISO on admininstrative leave under investigation for raising alarm about DOGE access
named:
- Tyler Hassen
source: https://www.nytimes.com/2025/03/31/us/politics/doge-musk-federal-payroll.html
- date: 2023-03-29
event: Two DOGE staffers are granted admin access to the FPPS payroll system at the Department of the Interior
type: access_granted
access_type: admin
access_systems:
- FPPS
named:
- Stephanie Holmes
- Katrine Trampe
source: https://www.nytimes.com/2025/03/31/us/politics/doge-musk-federal-payroll.html
systems:
- name: Federal Personnel Payroll System
id: FPPS
description: A shared service which processes payrolls for the Justice, Treasury and Homeland Security departments, as well as the Air Force, Nuclear Regulatory Commission and the U.S. Customs and Border Protection, among other federal agencies.
risk: PII and payment info for federal staff at several large agencies, including the ability to interfere with pay
pia: https://www.doi.gov/sites/doi.gov/files/fpps-pia-revised-04222020_0.pdf
cases:
- name: Center for Biological Diversity v. U.S. Department of Interior (D.D.C.)
description: Plaintiffs, a nonprofit organization focused on habitat preservation for endangered species, alleges that DOGE and the Department of Interior have violated the Administrative Procedures Act by failing to follow Federal Advisory Committee Act (FACA) requirements
case_no: 1:25-cv-00612
date_filed: 2025-03-03
link: https://www.courtlistener.com/docket/69698261/center-for-biological-diversity-v-us-department-of-interior/But it was starting to get more unwieldy to edit. And sometimes, when I was dealing with a single event that affected multiple agencies for instance, I would need to duplicate and move content around. That made it harder to ensure everything was consistent. So, the next big step was to define a workflow where I would edit raw data and then a pre-commit hook could be used to regenerate files downstream. Under this model, I defined a few files with basic types that I can then join into more complicated data structures, I could then use the raw data to create files that are derived from processing the source files and combining information. Using this approach, I could edit a few source files and then generate other files from the data. This is the key change that powered the next iteration of the IT Modernization dataset.
DOGE Track
It was time to make the “IT Modernization” dataset its own project. Following these lines, I created a new repository named doge_track on May 7, 2025 and copied over the existing data from Trump Data to there. From there, the immediate next step was to build a website.
The main thing to understand about me is that I am really cheap and I didn’t want to spend a lot of money every month just to keep a website up and running. Static site generation seemed like the best option to use here because this is content that doesn’t change that frequently (at most, several times a day) and that does not need to serve personalized information to different users. I love static sites because it’s a simple approach that scales tremendously for peanuts, especially since there are several providers who offer free accounts for static site hosting.
In fact, the only money I have spent on DOGE Track was to buy a license for Font Awesome and the domain dogetrack.info. The DOGE Track website currently runs in a free tier on Render
To make this happen, I picked the same Bridgetown library that I have used for this site as well. I had originally considered using a similar static generator in Python, but what I like about Bridgetown (as well as its predecessor, Jekyll) is that it’s very easy to integrate data into page generation by adding YAML files to the _data/ directory. These can then be referenced in templates which use either Liquid or embedded Ruby to let you iterate over things. Eventually, I redesigned the site to just call a database directly for data, but it was a helpful way to build the site initially.
For the front end, I used Tailwind CSS and DaisyUI, because it seemed like interesting tech I wanted to learn and a coworker recommended it. I have enjoyed the highly granular control over formatting I get with Tailwind, but if I were doing it today, I would probably take the time to learn proper web components
But I didn’t have the time. New events were happening every day. It was important to keep up. And so since then, it has continued to be an obsessive project of mine. Over the past year, I have added lots of data, but I have made a lot of changes to how the data is stored and how it is presented, both on big screens and mobile phones.
I don’t know when I will stop working on this project. Even now, I am considering new ways to present what is happening each month, filling in information about prior affiliations (like Tesla) or post-DOGE jobs and providing more context on what DOGE has been doing to further its projects across the government. I don’t know when DOGE will truly end, but I do know this work continues to keep me engaged. It has given people insight into what is happening. And it provides me with a way to channel my anger so I can bear witness in the hopes that one day these people will be held accountable.